Pagination has been part of web applications since the dawn of dynamic content. In order to sustainably serve category or search result pages with more than a hundred items, they need to be split into multiple pages to prevent database resource exhaustion and overly long loading times / page sizes. But just because this problem is old doesn't mean it is easy.
The simple approach
When getting started with building paginated queries, the first solution that comes to mind is to use LIMIT and OFFSET:
SELECT * FROM demo LIMIT 10 OFFSET 20;While the query is rather simple, it has a few desirable features: It is short and easy to read, does not depend on any table column or column's data to work, and can be used to create stable "page numbers" by simply multiplying the page number * results per page and using that as the OFFSET.
This query works fine as long as the number of rows to skip with OFFSET remains small, but the larger the OFFSET value, the slower the query becomes. When looking at the EXPLAIN output, the reason becomes obvious:
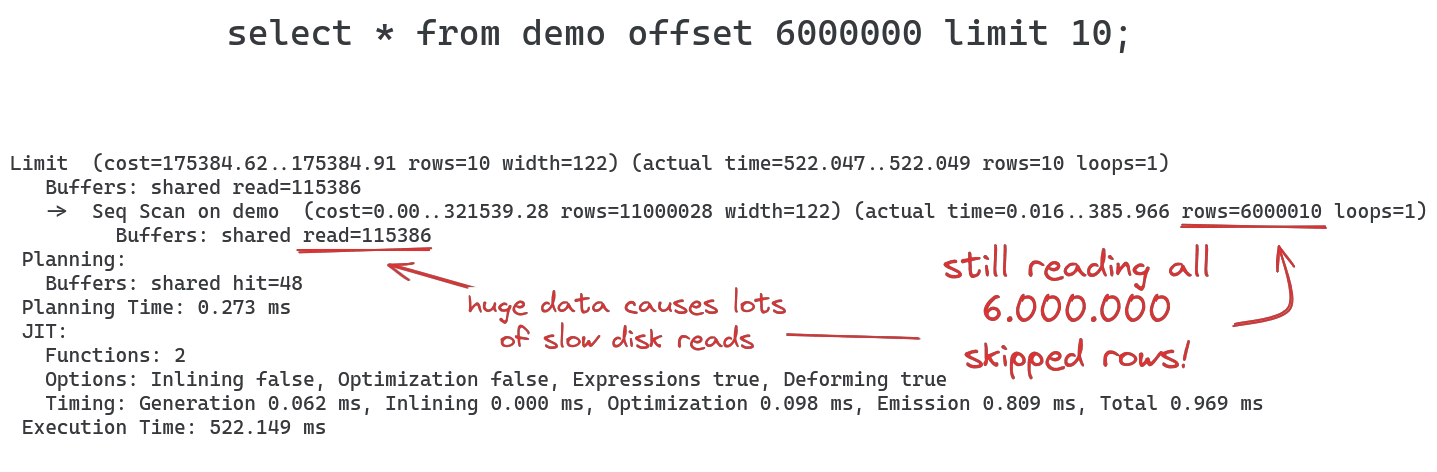
This is the inherent problem with using OFFSET for pagination: all skipped rows are still read from the table before the OFFSET is applied to remove them, making this approach unsuitable for larger datasets that still need
Improving speed with keyset pagination
The term "keyset" pagination refers to using a set of one or more "keys" (typically indexed columns) for pagination instead. Since looking up a known index element is fast, it can be used to "seek" through an index and handle pagination. Instead of skipping a known number of rows, you would use the key(s) of the last element of the current page to fetch the next n rows for the next page:
SELECT * FROM demo WHERE id > 6000000 LIMIT 10;Looking at the query plan makes it obvious why this is significantly faster:

Instead of reading all the skipped rows from the table and then excluding them, they are excluded in the reading step by the filter condition. This will remain almost the same speed no matter the size of the table or offset.
While the speed is impressive, it does come with a different set of problems:
the table needs a sortable column to filter on, preferrably with a sortable index (like a primary key)
sort order needs to be stable between queries. When using a column like a timestamp for pagination, a secondary unique column is needed to decide in which order duplicate values of the first column are sorted. This means an index supporting the query will need to contain more than one column, increasing memory usage
the query needs to know the last value for the filter column when fetching the next set of items, so using simple page numbers may not work
static page links cannot be reliably generated, because primary key values may contain holes (from deleted rows or rows excluded by filters), so statically linked pages may contain less than the desired amount of rows (or none at all)
Alternative solutions
Since both approaches have their respective drawbacks, applications needing to paginate large tables often adopt one or two approaches to try and get a better tradeoff:
Limit
OFFSETdepth: For many applications, there is no need to allow arbitrarily long result sets, so limiting the maximum results to a hundred can mitigate the problem altogether. Sacrificing this piece of functionality will be worthwhile especially for applications providing search results or recent activities in a news feed, as only the first few pages are of primary interest to the user.
Keyset pagination with lookup tables: The second approach reintroduces semi-stable page numbers for keyset pagination by using application logic in the background to recalculate the column offset values for each page and storing them in a temporary table or materialized view. When a page is requested, the query would first look up the key offset value in that table, then use that for a keyset-based query. This approach requires that the lookup table is refreshed regularly to account for missing/deleted rows, and that query results do not vary (i.e. no dynamic filters are applied that may exclude rows from the result set).