Combining multiple commands using pipes and stream redirection is a common task in the linux command line. While shells like bash already offer the most common tools to manage streams, some advanced features are missing. One of these features is copying an input stream to multiple output targets - that's what tee does.
How the tee command works
The tee command is very similar to a pipe or output redirection operator in bash, but with a slight difference: it can copy stdin to more than one output. By default, stdin will always be copied to stdout - but additionally, it can be copied to one or more files on the fly as well.
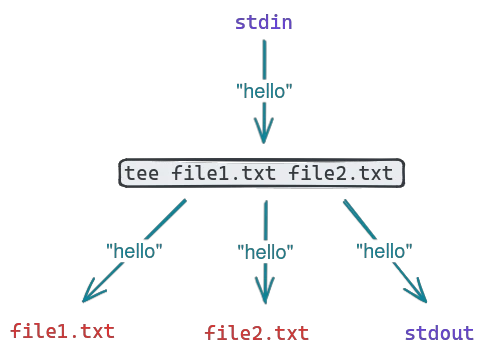
The tee command takes one or more files as arguments, and can be chained between other commands to copy the stream between them:
Note that by default tee will override the content of the files given to it. If you want to append to them instead, use the -a flag:
echo "text" | tee -a log.txt | wcNow the file log.txt gets appended to with each run, rather than overridden.
Debugging complex pipes
One common use of the tee command is to debug commands that consist of many individual commands chained together. Consider this example:
sample_command | grep "error" | wc -lThis is a relatively simple command chain, but it may be annoying to debug: if the output of wc - l at the end is 0, it could either mean that there were no errors, or that the grep pattern didn't catch the error messages. Maybe the log messages use words like "warn" or "fatal" to log errors, and not the literal word "error".
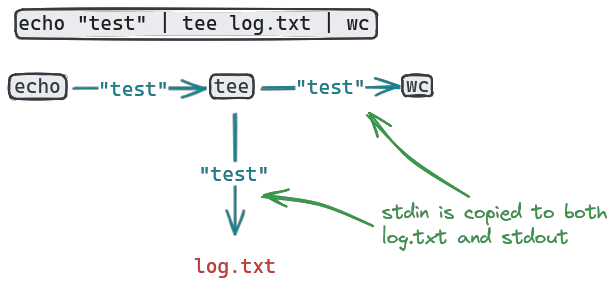
In this case, knowing the intermediate output of the first command can be useful, so copying it to a file with tee can be helpful:
sample_command | tee log.txt | grep "error" | wc -lNow the raw output of sample_command is available in the file log.txt for debugging. This is obviously silly for such a small command chain, but for pipes chaining 10 or more commands together it becomes a valuable tool.
Watching live log output
When fetching logs from a file in realtime, you are stuck between a rock and a hard place with only bash builtins: Of course you could use redirecting:
tail -f access.log | grep --line-buffered "/api/v1/auth" > auth.logBut this comes with a problem: You can't see what's happening. How many lines were written to auth.log? Is it enough data for troubleshooting? How long should the command run? You would need to start a second terminal session and check the contents of auth.log manually to know - or use tee:
tail -f access.log | grep --line-buffered "/api/v1/auth" | tee auth.logSince tee always copies to stdout, you can now see what gets written to auth.log in realtime.
Writing to restricted files
Sometimes you may want to write output to a file owned by root. The straightforward solution is to run the command generating the output with sudo and redirecting into a file:
my_command > /root/log.txtBut this may have a lot of side effects: Everything that my_command does now has root privileges. For long-running services or software that interacts with user input, this is often ill-advised, as a single bug in the software may give immediate root access to the server to an attacker.
To write the output of a program that shouldn't have root privileges (or that you don't trust), you can use tee to only only give the writing process the permissions to access the file:
my_command | sudo tee /root/log.txtNow my_command does not have any elevated privileges, and only tee is affected by the sudo command to be able to write to the protected file.
Fixing buffering issues
When dealing with realtime streams, you may occasionally see tee lagging behind it's input. This can be caused by the shell's buffering behavior: by default, streams are buffered into chunks before passing them down the chain. Buffering can be altered through the stdbuf command.
Buffer full lines:
stdbuf -oL ping example.com | tee log.txtDisable buffering:
stdbuf -o0 ping example.com | tee log.txtWhich buffering mode works for you depends on the command you are running, but be warned that disabling buffering altogether may have a negative performance impact for large output streams.